

Title: Full Parameter Fine-tuning for Large Language Models with Limited Resources
PDF: https://arxiv.org/pdf/2306.09782v1.pdf
Code: https://github.com/openlmlab/lomo
大型语言模型(LLMs)在自然语言处理(NLP)领域产生了革命性的影响,但对于训练而言需要大量的GPU资源。降低LLMs训练的门槛将鼓励更多的研究人员参与,从而使学术界和社会受益。虽然现有方法主要集中在参数高效的微调上,即调整或添加少量参数,但很少有方法解决使用有限资源对LLMs的全部参数进行调整的挑战。本文提出了一种新的优化器,即低内存优化(LOMO),它将梯度计算和参数更新融合为一步,以降低内存使用量。 通过将LOMO与现有的内存节省技术结合起来,与标准方法(DeepSpeed解决方案)相比,本方法将内存使用量降低到10.8%。 因此,本文方法使得在单台配备8个RTX 3090的计算机上,每个显存为24GB的情况下,可以对65B模型的全部参数进行微调。
大型语言模型(LLMs)已经在自然语言处理(NLP)领域产生了革命性的影响,展示出了出人意料涌现(emergence)能力。然而,训练这些拥有数十亿参数的模型,例如具有30B到175B参数的模型,为NLP研究设下了更高的门槛。调整LLMs通常需要昂贵的GPU资源,例如8×80GB设备,这使得小型实验室和公司难以参与该领域的研究。
最近,出现了参数高效微调方法,如LoRA和Prefix-tuning,为使用有限资源调整LLMs提供了解决方案。然而,这些方法并没有针对全参数微调提供实际解决方案,而全参数微调已被认为比参数高效微调更强大。在本文中,我们旨在探索在资源有限的情况下实现全参数微调的技术。
本文分析了LLMs中内存使用的四个方面,即激活、优化器状态、梯度张量和参数,并在三个方面优化了训练过程:
- 本文从算法的角度重新思考了优化器的功能,并发现在对LLMs进行全参数微调方面,SGD是一个很好的替代方法。这使我们能够删除优化器状态的整个部分,因为SGD不存储任何中间状态。
- 本文提出的优化器LOMO将梯度张量的内存使用降低到O(1),相当于最大梯度张量的内存使用。
- 为了稳定LOMO的混合精度训练,本文在训练过程中整合了梯度归一化、损失缩放和将某些计算转换为全精度的方法。
本文技术使内存使用量等于参数加激活和最大梯度张量的使用量,并将全参数微调的内存使用推向极致,使其仅相当于推理的使用量。值得注意的是,使用LOMO节省内存时,本文方法可确保微调过程保持不受损害,因为参数更新过程仍等同于SGD。
本文通过实证评估LOMO的内存和吞吐性能,并展示LOMO的使用使得仅通过8个RTX 3090 GPU即可成功训练一个65B模型。 此外,为验证该技术在下游任务中的表现,我们将LOMO应用于对SuperGLUE数据集收集的LLMs全参数微调。实证结果证明了LOMO在优化具有数十亿参数的LLMs方面的高效性和有效性。本文贡献如下:
- 提供了理论分析,表明SGD可以成功对LLMs进行全参数微调。以前妨碍广泛使用SGD的问题在微调LLMs方面可能不再是严重问题。
- 提出了一种名为LOw-Memory Optimization(LOMO)的方法,大大节省了GPU内存使用,而不会损害微调过程。
- 通过对内存使用和吞吐性能进行彻底评估,我们从实证上验证了LOMO在资源有限的情况下优化LLMs的有效性。
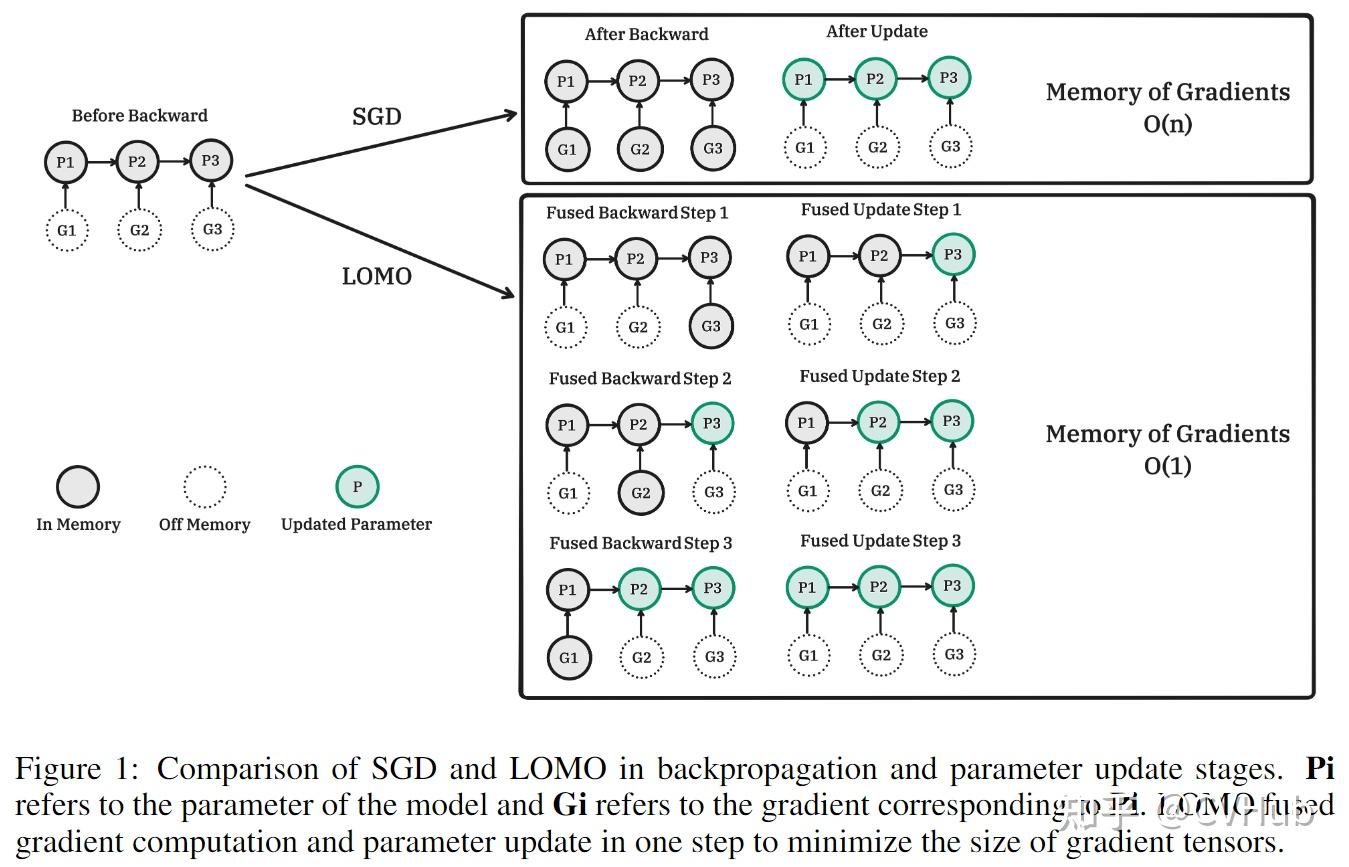
其中,Pi表示模型的参数,Gi表示对应于Pi的梯度。LOMO将梯度计算和参数更新融合为一步,以最小化梯度张量的大小。
优化器状态占据了用于训练LLMs的大部分内存。像Adam这样的现代优化器会存储比参数大两倍的中间状态。随着参数的增加,优化器状态成为内存使用的主要项。
尽管Adam在训练深度模型方面取得了巨大成功,但我们能否使用一种更廉价的优化器来对LLMs进行微调?
很显然,SGD作为一个基本优化器,对于微调LLMs是一个可接受的解决方案。以前的研究经常讨论SGD的三个挑战:
- 曲率损失面积较大
- 局部最优
- 鞍点
现代优化器已经在处理问题1上显示出有效性,并且在某些情况下可以缓解问题2和3。然而,当我们限定范围为微调LLMs时,这三个挑战可能会有所不同。
- 更平滑的损失面
一个重要的假设是LLMs的参数空间非常平滑,对参数进行微小扰动不会导致损失变化太大。如果我们相信更大的模型具有更平滑的损失面,我们可以得出结论:问题1不是一个问题,因为LLMs的损失面不应该有很大的曲率。需要注意的是,这仅在我们训练LLMs进行自然语言任务时成立(或者如果使用代码进行预训练,则适用于基于代码的任务)。与预训练任务无关的合成损失函数确实会面临曲率较大的问题。
- 局部最优已足够好
微调的目标是在不显著改变模型本身的情况下,将LLMs调整到新的任务和领域中。因此,局部最优通常是一个足够好的解决方案,并且相对于预训练语料库而言,有限的训练数据使得将模型推向遥远的全局最优解变得困难。遥远的鞍点同样如此。同样,对于常见的NLP任务,LLMs的初始点应该在一个谷底中。如果模型是通过指令(任务)进行预训练的,这种现象可能会更加明显,因为我们有更多机会找到与新任务相似的预训练任务。鞍点通常出现在山脊上,并且与谷底有一定距离,因此如果我们不将参数从预训练的值改变得太远,可能不会遇到鞍点问题。
除了上述的定性讨论,我们希望对使用SGD微调LLMs的稳定性进行更深入的分析。假设我们有一个参数为的预训练模型
,一个训练集
,和一个损失函数
。在一个包含两个数据点的批次上,SGD的一步更新可以表示为:
其中是学习率,
和
是两个不同的训练样本。
接下来,对这两个训练样本和
依次进行两步的SGD更新,可以表示为:
根据微分中值定理,我们有:
其中是在
和
之间的一个点,我们可以看到方程
减去方程
等于
。假设损失面足够平滑,这一项可以忽略不计。这表明在平滑的损失面上利用SGD优化器可能意味着更大的批量大小。
正如我们上面提到的,合理地假设LLMs的损失面是平滑的,而更大的批量大小则表示更强的训练稳定性,因此我们相信使用SGD优化器对LLMs进行微调的过程是稳定的。这也解释了为什么SGD在小模型上失败而在大模型上成功的原因。
梯度张量表示参数张量的梯度,并具有与参数相同的大小,因此会导致很大的内存开销。现代深度学习训练框架(如PyTorch)会为所有参数存储梯度张量,主要出于计算优化器状态和梯度归一化的目的。
在我们采用SGD作为优化器的情况下,没有基于梯度的优化器状态,因此我们有一些替代方法可以用于梯度归一化。因此,我们提出了一种名为LOw-Memory Optimization(LOMO)的方法,将梯度计算和参数更新融合为一个步骤,以避免存储任何梯度张量。
具体而言,我们可以将传统的梯度下降表示为,
,这是一个两步过程,首先计算梯度,然后将其更新到参数。而融合版本则是
。
核心思想是在计算梯度时立即更新参数,这样就不需要将梯度张量存储在内存中。 可以通过在反向传播中注入钩子函数来实现此目的。PyTorch提供了相应的API用于注入钩子函数,但是目前的API无法实现精确的立即更新。因此,我们最多只需在内存中存储一个参数的梯度,并且在反向传播期间逐个更新每个参数。这种方法将梯度的内存使用量从存储所有参数的梯度减少到仅存储一个参数的梯度。
LOMO方法的内存使用量与参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法相当,这意味着将LOMO与这些方法结合只会稍微增加梯度占用的内存。这使得可以在PEFT方法中调整更多的参数。
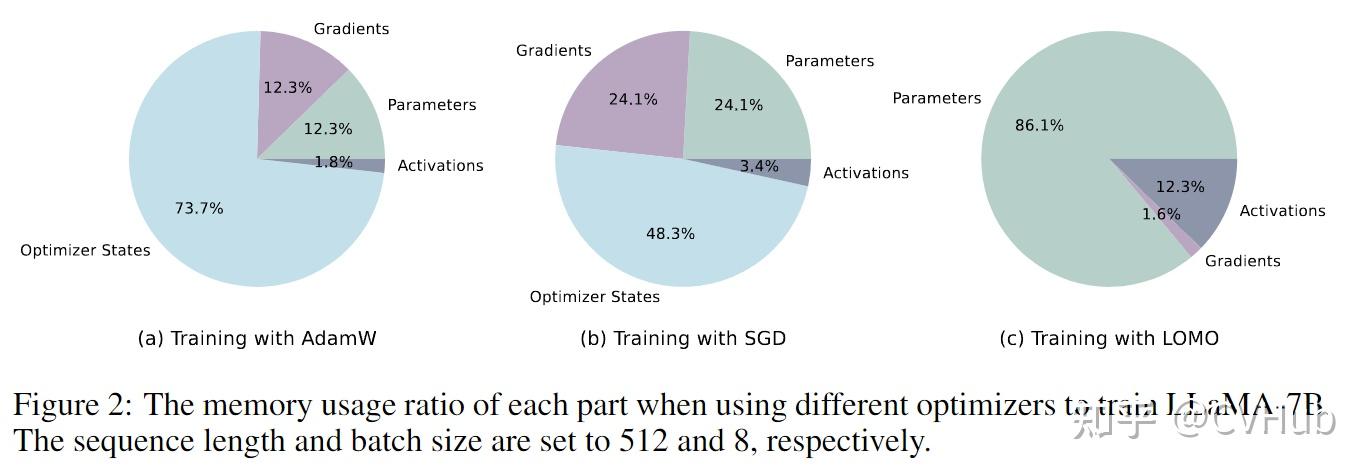
使用不同优化器训练LLaMA-7B时,每个部分的内存使用比例。序列长度和批量大小分别设置为512和8。
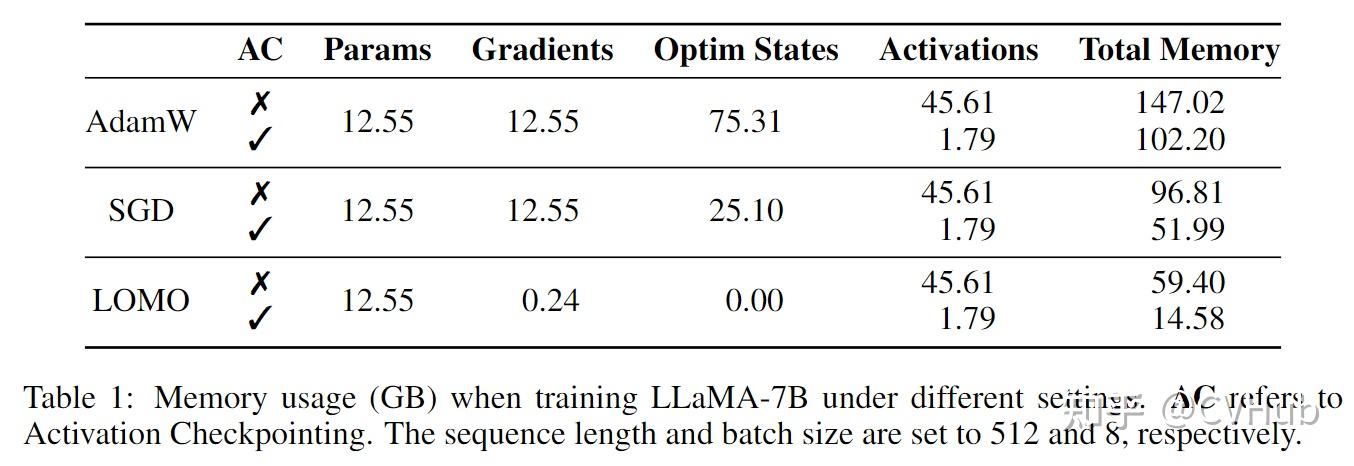
在不同设置下,训练LLaMA-7B时的内存使用量(以GB为单位)。AC表示激活检查点技术。序列长度和批量大小分别设置为512和8。
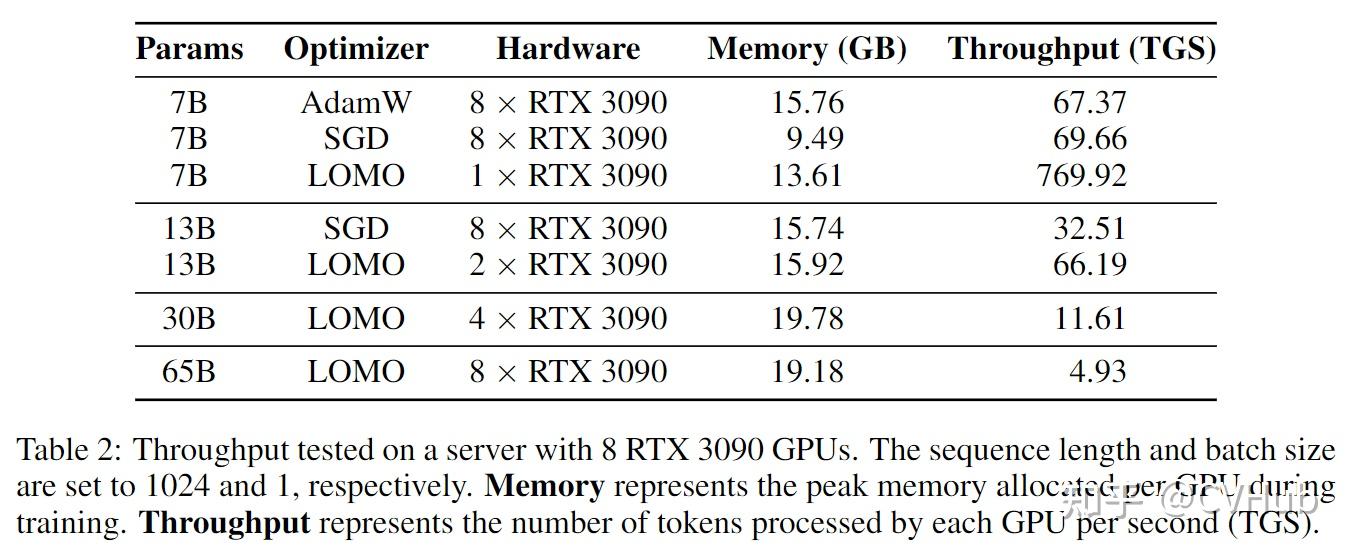
在具有8个RTX 3090 GPU的服务器上进行的吞吐量测试。序列长度和批量大小分别设置为1024和1。内存表示训练期间每个GPU分配的峰值内存。吞吐量表示每个GPU每秒处理的标记数量(TGS)。
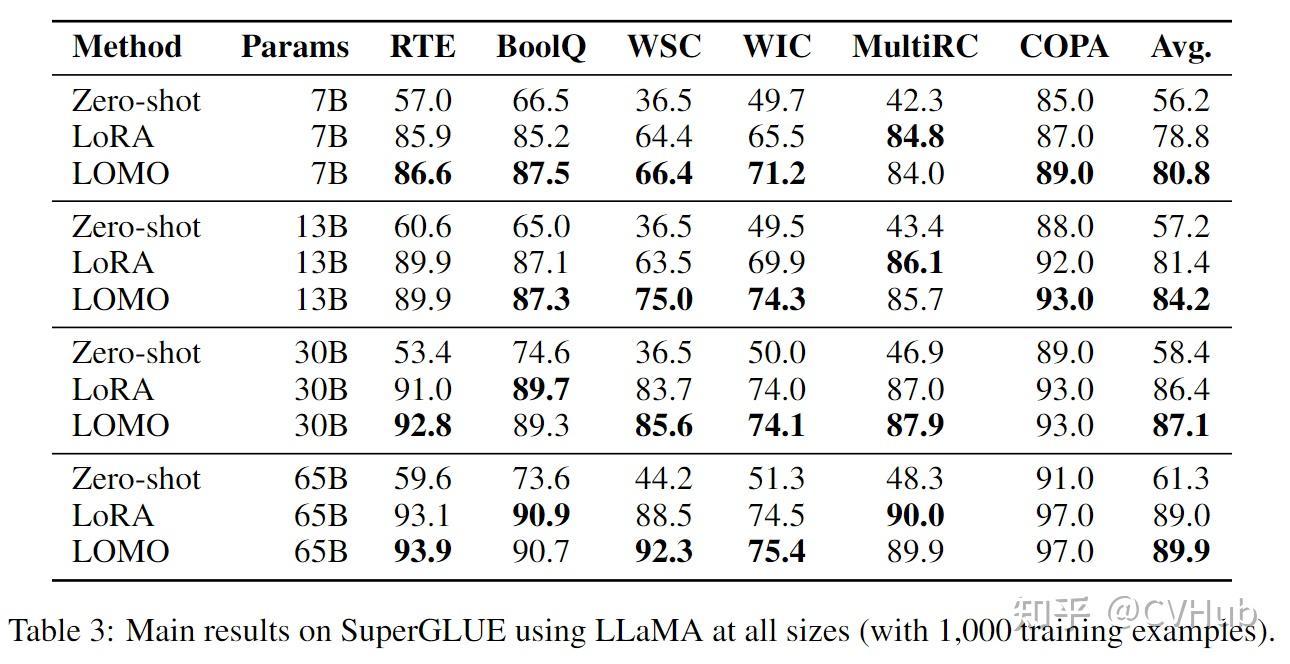
在使用LLaMA的各种规模(使用1,000个训练样例)上,对SuperGLUE的主要结果进行了总结。
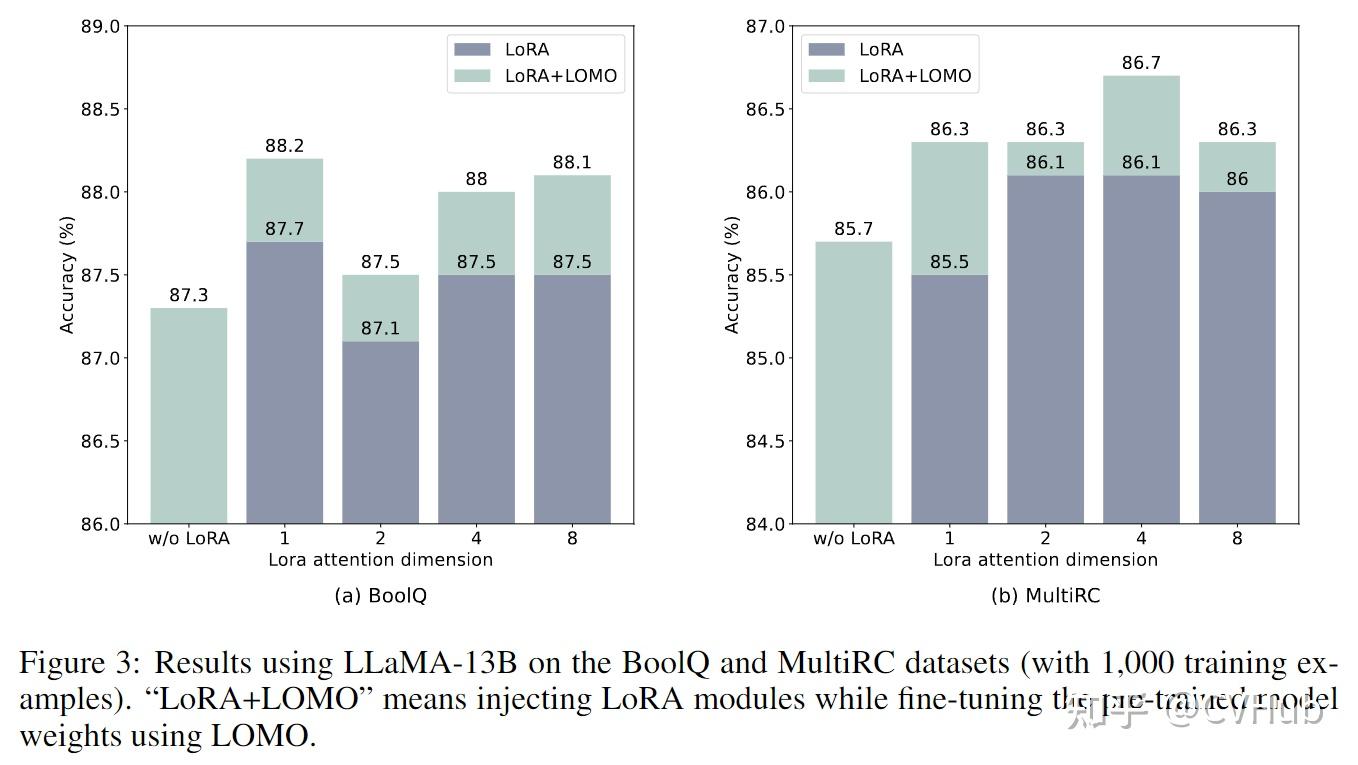
使用LLaMA-13B模型在BoolQ和MultiRC数据集上的结果(使用1,000个训练样例)。"LoRA+LOMO"表示在使用LOMO对预训练模型权重进行微调时,注入了LoRA模块。
本文介绍了一种名为LOw-Memory Optimization(LOMO)的新型优化器,旨在利用有限的资源实现对大型语言模型的完全参数微调。本文展示了在配备RTX 3090等消费级GPU的服务器上对65B模型进行微调的可行性。通过分析LOMO的内存使用情况,进行吞吐量测试,并在SuperGLUE数据集上进行实验,本文展示了它的有效性和潜在影响。
随着大模型时代的来临,未来很重要的一部分工作是进一步降低训练大型语言模型所需的资源门槛,从而使更多人能够访问和采用这些模型。目前,当使用LOMO进行训练时,大部分内存都被参数占用。因此,一个有希望的方向是研究参数量化技术,可以显著减少内存使用。此外,本文还将探索更多适用的场景,深入研究优化大型语言模型的理论分析,这对推动该领域的发展具有重要价值。
下列学习资料的 PDF 版本,欢迎添加小编卫星号:cv_huber,备注“知乎-xxx资料”即可领取。

